Simulation
Neural Network Training
After rerunning the training several times, we found that the simulated system consistently converged to reasonably ideal behavior at around 200-300 episodes. After this amount the pendulum was reasonably able to balance itself for an extended period of time. We deemed this portion successful enough due to the matching of expectations and reproducability of the results and thus decided to use the computed NN as the building block for the remaining parts.
Attack Detection
A potential attack detection algorithm needed to account for some specific considerations since the eventual target would be an embedded device in real time operation. The attack detection algorithm would need to make a judgement about the attack status in real time, with only prior readings to use as a bases for evaluation. Additionally, memory usage would need to be taken into consideration since storing the entire history of health scores up until time t would be largely impractical for a limited memory system. Finally, a third objective was to output the attack flag as high only during the duration of the attack and NOT during the recovery period.
Before determining the duration of the attack, the prelimary step of determinging the tripwire (the beginning of the attack) needed to be solved first. Among examining several profiles the most obvious pattern that started to emerge was a sudden spike or drop in the health score (signficantly deviant from the average until that point) at the moment of attack. In this regard, we decided to use a threshold on the delta of the health score as the metric of measurement - an abnormally high delta or a sudden drop in the health score would thus trigger the attack detector.
Next came the problmem of figuring out the duration of the attack. Several variations on the impulse attack indicated that the resulting health score profile exhibited a parabolic (albeit noisy) shape with the minimum value roughly occurring at the time at which the attack ceased. This provided the basis for which the detection algorithm was determined; however, the noisy behavior needed to be dealt with first.
To allow for smoothing of the readings, we decided to employ a lower sampling rate that polled roughly once only every 30 timesteps. At least for the trials conducted in this experiment, this rate skipped over enough of the noise in between sampling steps to approximate the overall behavior. However, it should be noted that this value was mainly tuned for the health score profiles based on the settings of the simulation - in general, this would be a hyperparameter that would need to be adjusted after running numberous sample attacks of this variety on the system in question.
The health scores between the prior sampling time and the current sampling times were averaged in order to compute the measurement metric for the attack detection (essentially a sliding window average). In general, a decline in the average health score was interpreted as an ongoing attack, while an increase could be interpreted as recovery. The simplicity and perhaps naivete of this process can largely be attributed to the observation that this detection needed to occur in real time with access only to previously recorded information. Furthermore, since the eventual practitioner of this algorithm was intended to be an embedded device, memory usage needed to be taken into consideration. The sliding window average approach biases the computation at time t towards values closer to that of the value at time t, which was ultimately considered desirable from a functionanal and computational efficiency standpoint. Furthermore, the collection and storage of averages was not necessary until the attack flag was tripped high, thereby further reducing the memory requirements.
Once the profile began showing an upward trend at a particular sampling time step, the attack was deemed as commplete and the controller was classified into "recovery mode". Normal operation was expected to resume only when the score eventually exceeded a particular minimum threshold (in our case a health score of roughly 75-80); however, if the controller never rebounded back to this threshold, then the controller would be considered beyond salvaging and would need to be quarantined from the system. As with the sampling rate, this too would need to be a hyperparameter tuned to whatever is deemed best for the system in question.
Employment of the aforementioned algorithm resulted in the following detection profile based on health score values:
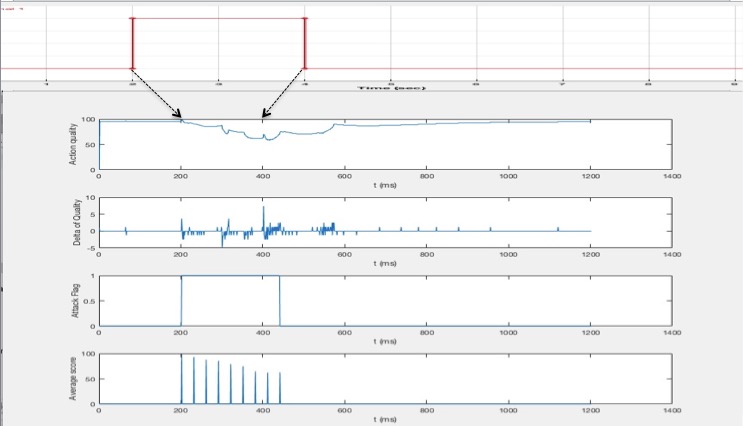
From top to bottom, the profiles in the above diagram represent the impulse attack, the overall health score profile, the deltas (slopes) of the profile, the status of the attack flag, and the average health score at each sampling time step. As can be observed, the above attack algorithm does a fairly decent job of identifying the window of attack subject only to a 1-sampling step error. The reduced sampling rate indeed smoothes out a lot of the noise in the original profile score, and leads to an accurate determination.
However, it is important to note here that this algorithm was developed by making several assumptions about the nature of the attacks - particularly in their behavior resuling in a general parabolic health score profile shape. This of course is not necessarily the case for all kinds of attacks. For example, an application of this algorithm to the white noise attack results in the following profiles:
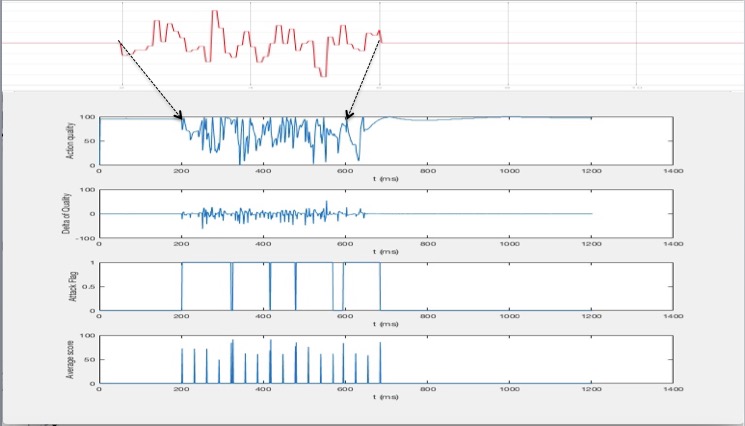
While the resulting attack flag status is surpringly not bad given the window of attack, it is not nearly as smooth and, for the most part, looks almost entirely coincidental based on the observation of the average score profile. But in general, an algorithm constructed with some assumptions about the nature of the attack of course does not scale to all attack varieties. In order to make an accurate determination of the attack window across a variety of attacks, one would need to make a guess as to what attack is occurring at any point in time. This prediction problem naturally suggests a machine learning appraoch and is certainly worth some exploration as future work.
Attack Correction
Employing the attack correction algorithm in the context of a white noise attack, we obtained the following profiles:
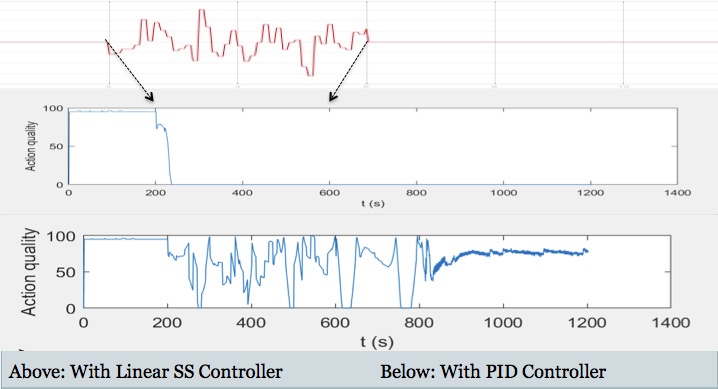
As mentioned previoulsy, use of the linear state space controller resulted in a degenration of the angular state space controller and a drop in the health score profile to 0 (from which it could never recover). However, substituion of another PID controller addresses this problem. While the primary controller is under attack (the action quality in this case reflects only the actions take by the PID controller(s) and not the overall system), the Neural Network actively manages the system. When the attack is concluded, the handoff is made back to the PID system. Though it does not immediately recover back to the same health score that it had when there was no intervention, the patter still suggests an upward trend toward an acceptable threshold; however, the handoff will never quite be as efficient. That being said, the results of this experiment definitely demonstrated promise in the approach.
Physical Testbed
Neural Network Training
After several rounds of debugging, we managed to integrate all of the drivers and communication systems together to be able to train the system autonomously (subject to manual intervention to reset the pendulum vertically after each episode). A video of the execution of a few steps in the training process is displayed below:
The left side of the screen shows the program running on the target (in an SSH session) while the right is the Matlab instance running on the host (which admittedly is not of the best quality). Note that these trials were at the beginning of the training and thus the exploration phase probability was nearly 100%. Therefore all of the actions are random and would almost certainl result in fast failure.
However, while we did have success in establishing the entire communicaiton and actuation pipeline, after repeating this exercise for nearly 200 pain-staking episodes, the system did not converge at an end state that we had hoped for. We suspect this in large part is due to a combination of mechanical limitations of the system, integrity of values from the sensors and actuators, and potentially an unoptimally chosen reward function; however, each of these potential sources of error would need to be systematically debugged before a known root cause could be identified. We also noticed that the system failed much faster than the simulation, and as a result consistently had much fewer data points to report. This would no doubt have implications in training the NN via RL since more data would have certainly reuslted in better training. Unfortunately, we ran out of time during the quarter to perform this systematic analysis, and thus need to declare it as future work to be done. In addition, each of these training runs takes a large number of man hours without automation of the reset to the apogee, further compounding the importance of solving the swing up problem.
PID Tuning
Tuning of the PID Controller proved to be a lot more difficult than initially anticipated. In addition to the rotary encoder not always giving the most accurate readings, we found the tuning of the proportional, derivative, and integral gain of both the angle PID and x PID to be a essentially a guessing game. There were several times during the process where parameters that performed very well in one run turned out to completely flop several runs later, and many of our findings proved to be difficult to reproduce. However, we did manage to eventually arrive at some parameters after discovering that the derviative gain was not being added correctly. Eventaully after tweaking the parameters some more, we constructed the following profile of the gains:
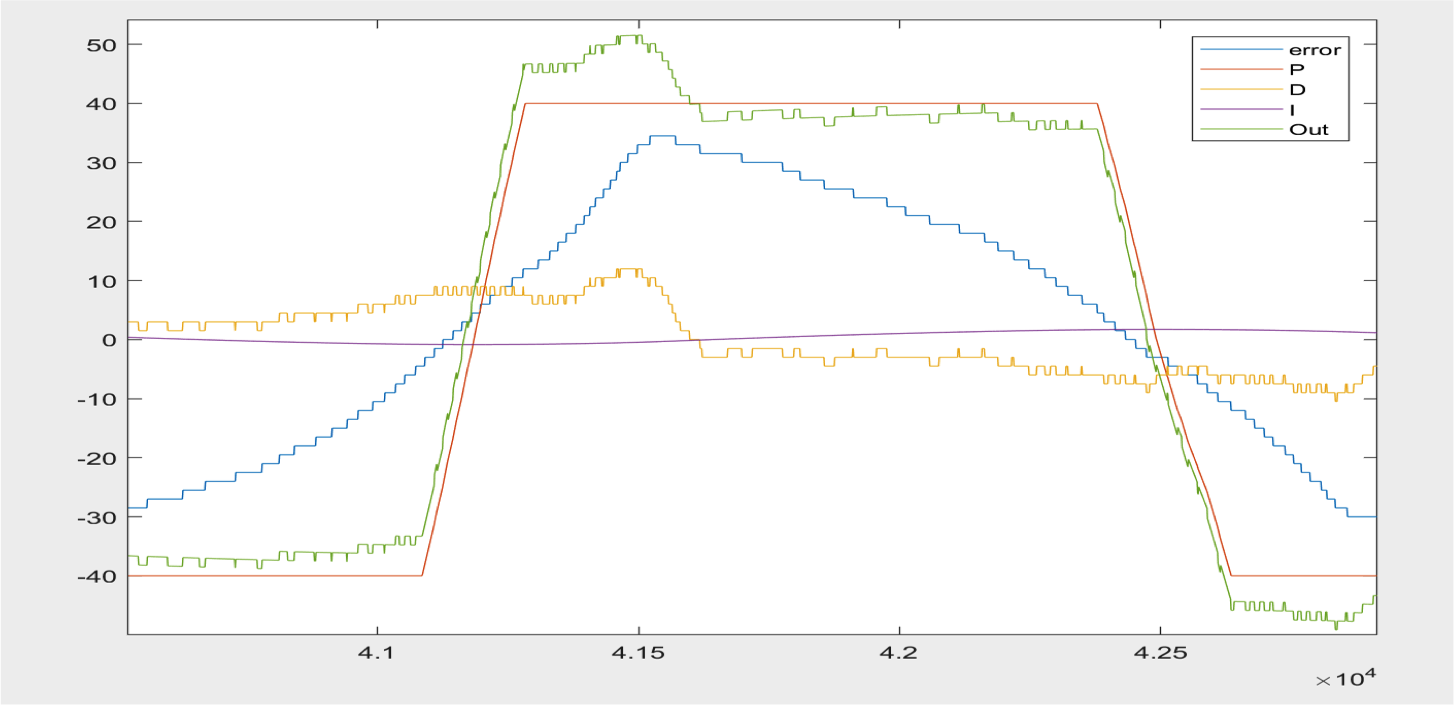
In the above plot we focus primarily on the proportional and derivative gain as these were the most important contributors to the system. After a lot of tweaking, we found that the profiles finally behaved as expected. Essentially as the error (theta angle of pendulum offset from the balanced position of 0) increases and varies in rate of change, the proportional (P) and derivative (D) gain spike to prompt movement of the pendulum further in the direction of the error to catch the pendulum before it falls. The derivative gain essentially acts as a system damper in this case while the proprotional serves as the primary driver. Eventually we would expect the error to converge to 0 as the gain envelopes the error and reduces the magnitude of oscillation, but we only sampled points toward the beginning to observe that the controller was actually functioning as expected. Eventually we did achieve some success as can be seen in the following video:
In this case the pendulum fell as it reached the side because we set an automatic kill signal in the event that it deviated far away from the starting position. This was in large part due to the fact that there were many iterations in which it slammed into the side trying to keep the pendulum balanced, damaging the wood and sending screws flying in the process. However, it still balanced for quite a bit during this run. Unfortunately, the results were not reliable and highly reproduceable. This could be due to a variety of reasons from mechanical issues to control parameter tuning, but a systematic evaluation would require more time.
Attack Detection
As briefly mentioned before, while we do have an initial draft of the code ready for this portion of the project, testing and evaluating results would require a fully trained neural network and a very robust PID controller. Without both of these components, the health score computtion would be extremely volatile and computing the status of an attack flag would be pointless. We are confident in our simulation results and their extendability to physical systems; however, they rely on proper operation of the previous two parts of the system to warrant true testability. This is therefore also a very reasonable option for further work.
Attack Correction
As with attack detection, this module requires successful operation of all prior phases in order for the results to be valid; however, in time this too will become testable. For now, however, the code has yet to be written since there are a lot of earlier problems that need to be solved to reach this step. We are eager to report on the findings as soon as we can examine the results with confidence in the findings.
Discussion
As mentioned previously, we were very happy and confident in the findings of our simulation - they provided concrete evidence of merit in our work and a basis by which we could advance the project. The simulations could be iterated on quickly with ver little technical debt beyond some patches of code, and thus provided a great framework for prototyping our hypotheses and quickly iterating based on the feedback of the results. However, as is always the case with simulations, many aspects of a physical system were over simplified and had an adverse effect during the porting of the findings to a physical testbed. A prime example of this is the swing up problem - while we could simply abstract this away in a simulation, this was an issue that had real implications in a physical system: numerous additional man hours.
Additionallly, we found that we needed to iterate considerably on construction of the system since we found ourselves lacking the parts we needed very frequently, either because we did not anticipate needing to order something or because an item we did order turned out to not meet our performance expectations. We iterated over several servos, a potentiomeer, several structural components, and even pendulums during the course of this project and routinely discovered that waiting for parts took a considerable amount of time. Had we anticipated these problems in advance, we would have made starting on the physical testbed a much higher priority rather than waiting until 10th week to implment our simulations on a testbed we had to essentially build from the ground up.
While the simulations were run in software suites proven and tested in industry and academia, the modules of our physical testbed were almost entirely home made. Though the parts themselves may have been machined, writing the drivers and building the system was essentially a home-cooked activity which, while rewarding, introduced a lot of potential sources of error. While it may have been straightforward to test components on their own, bringing everything together into an integrated cyber-physical system signficiantly increased the sources of error. That being said, almost all the pieces are in place - once the training and PID tuning are complete, the remainder of the phases can commence pretty quickly for the physical testbed.
However, all of that being said, we are still extremely proud of the results of our simulations and the remarkable progress we were able to make on the physical testbed in such a small amount of time. The videos serve as evidence of our hard work paying off, even if only for small periods of time!
Further Work
We ultimately would like to get a paper out of this project and present our findings. However, there are quite a few areas for further work before that can happen. These tasks can be roughly organized into the following list in order of decreasing priority:
- Solve the swing up problem to automate physical testbed testing
- Potentially migrate to a more well established inverted pendulum physical testbed setup
- Finish training the neural network via RL on the physical testbed
- Accurately tune the PID conroller
- Run, test, and iterate on attack deteciton
- Build, run, test, and iterate on attack correction
- Generalize attack model to be flexible for a variety of attacks
- Clearly differntiate between true malicious attack and possible system noise
- Ensure minimal loss of health score during handoff between PID and NN during correction
- Refine and iterate on results to ensure high inetegrity and reproducability
- Get patent, make millions, and fly off into sunset in Gulfstream G500 with mimosa in hand
Conclusion
Overall, this was an extremely rewarding project with a lot of highs and a lot of lows. Above all, it served as a great introduction to security in cyber physical systems, cyber-physical systems in general, and really deep diving into a problem where we initially had very little knowledge about at the beginning. We consider our efforts reasonably, but not absolutely successful; however, we have learned valuable lessons regarding system construction that we will definitely remember moving forward. We are eager to take part in a similar process again, albeit perhaps with a break in between.